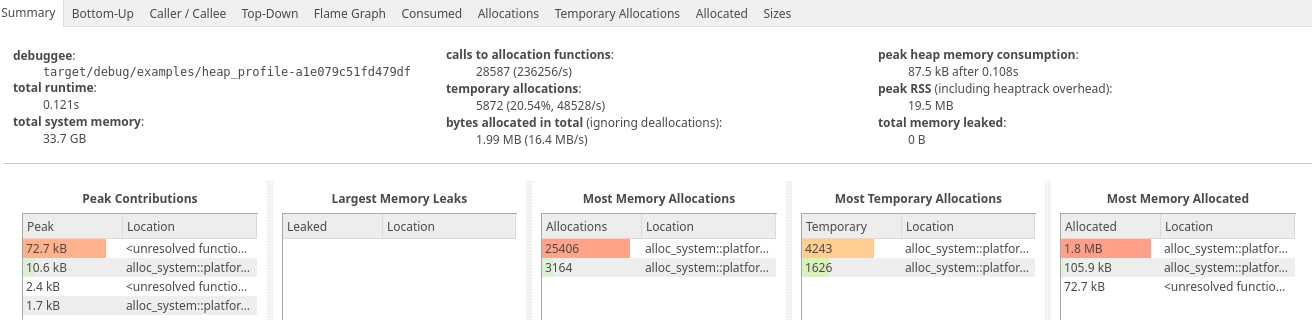
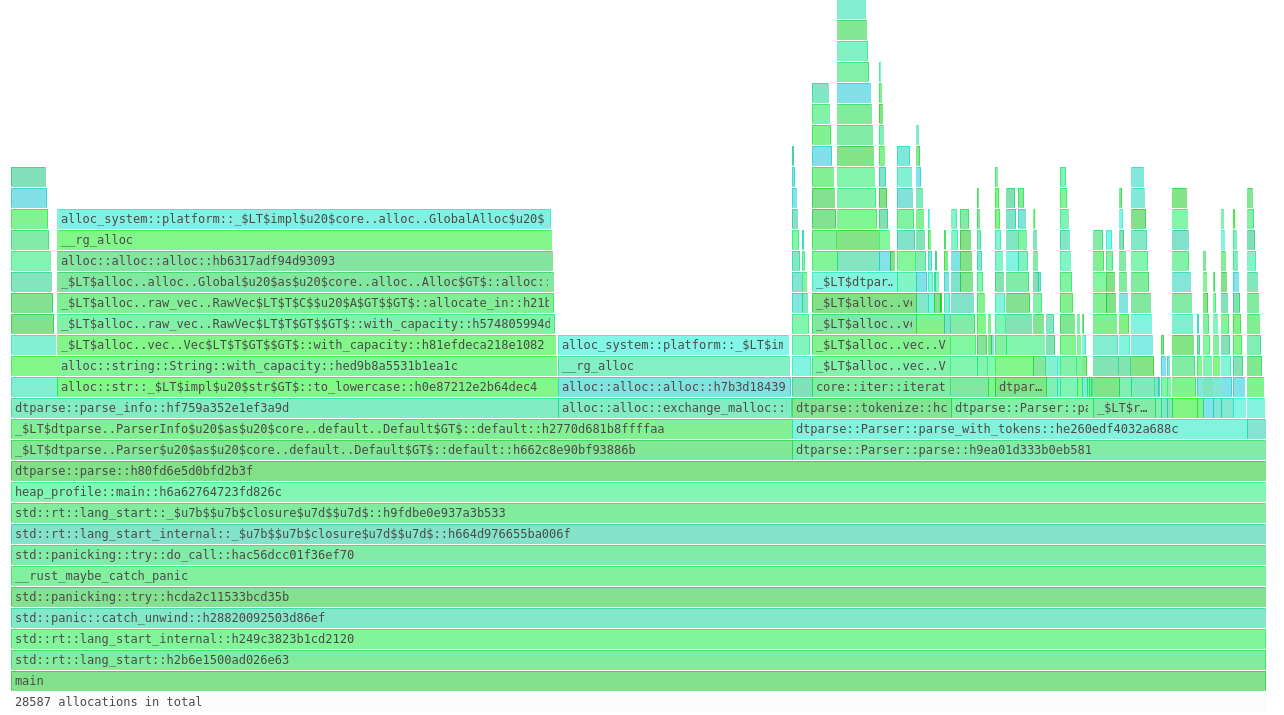
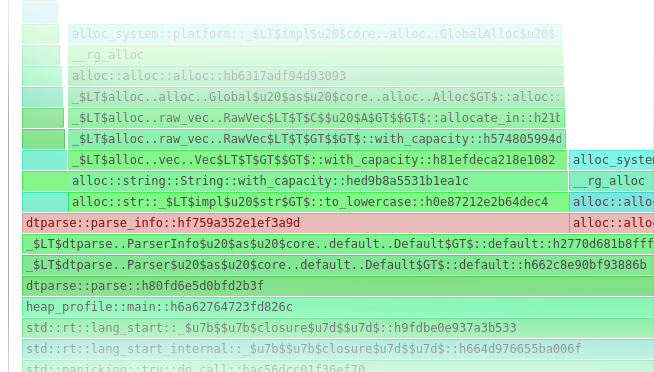
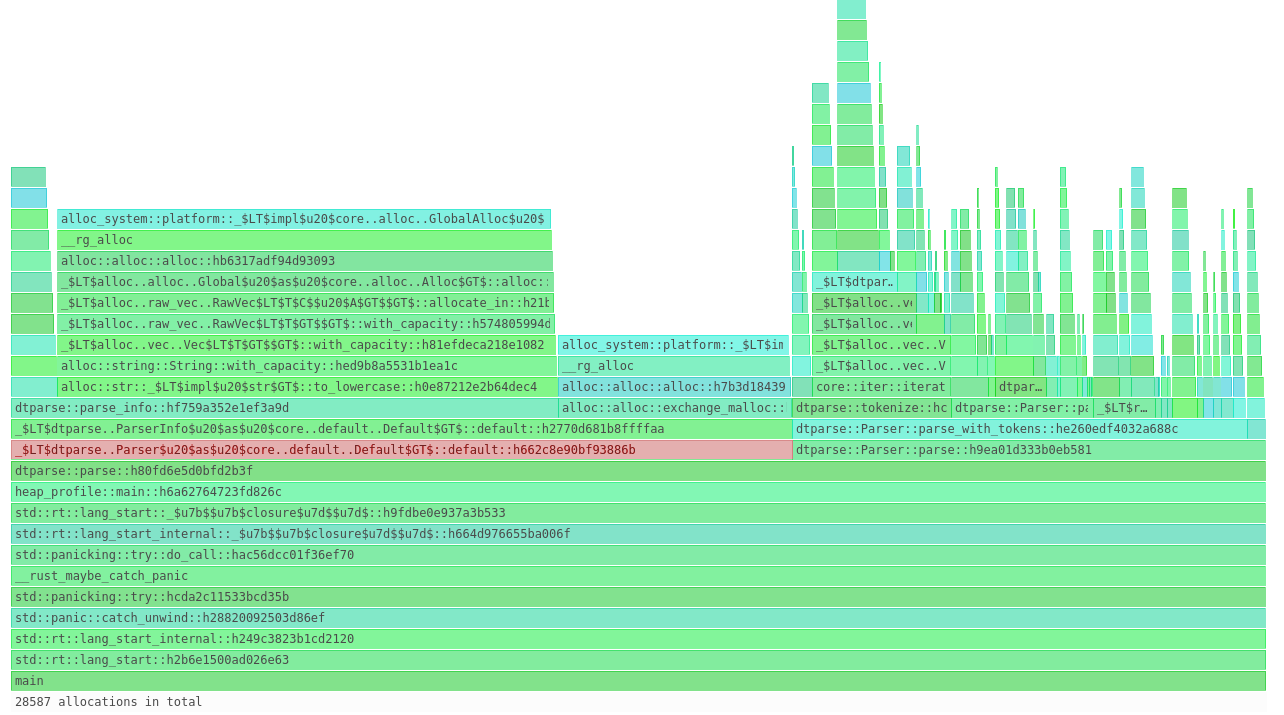
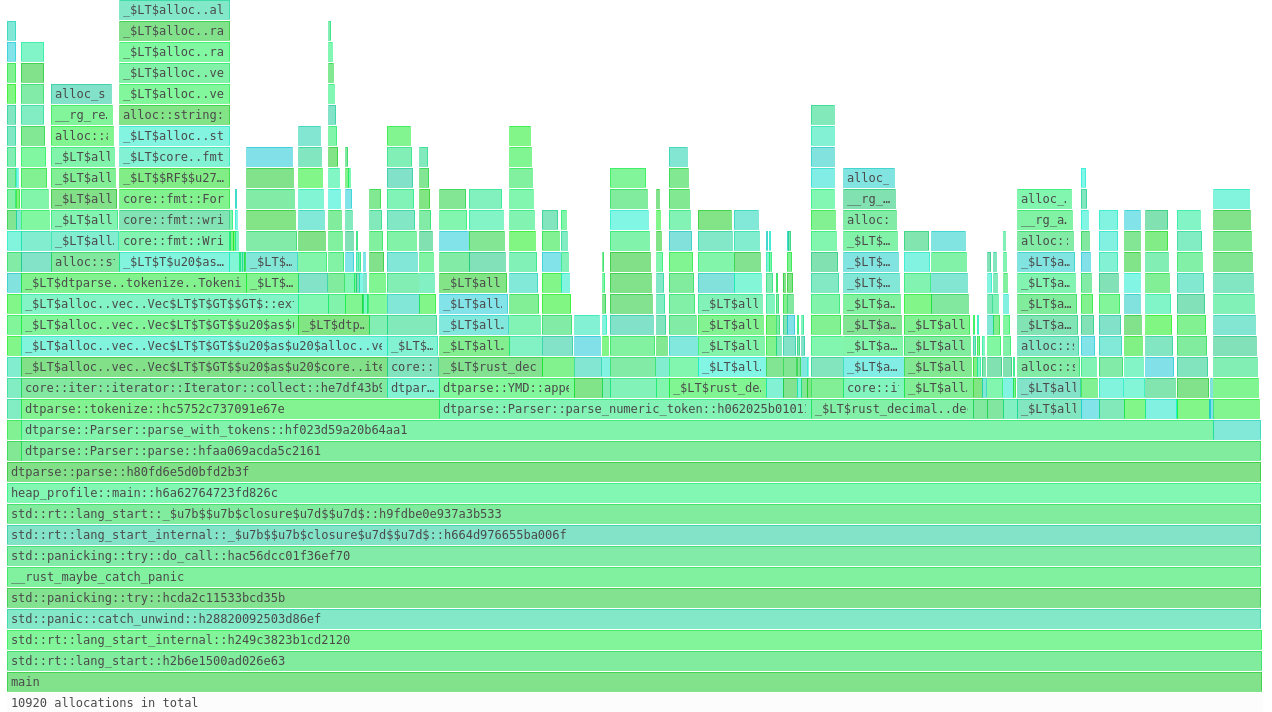
Prior to working in the trading industry, my assumption was that High Frequency Trading (HFT) is
+made up of people who have access to secret techniques mortal developers could only dream of. There
+had to be some secret art that could only be learned if one had an appropriately tragic backstory.
+

+
+How I assumed HFT people learn their secret techniques
+
+
How else do you explain people working on systems that complete the round trip of market data in to
+orders out (a.k.a. tick-to-trade) consistently within
+750-800 nanoseconds? In roughly the time it takes a
+computer to access
+main memory 8 times,
+trading systems are capable of reading the market data packets, deciding what orders to send, doing
+risk checks, creating new packets for exchange-specific protocols, and putting those packets on the
+wire.
+
Having now worked in the trading industry, I can confirm the developers aren't super-human; I've
+made some simple mistakes at the very least. Instead, what shows up in public discussions is that
+philosophy, not technique, separates high-performance systems from everything else.
+Performance-critical systems don't rely on "this one cool C++ optimization trick" to make code fast
+(though micro-optimizations have their place); there's a lot more to worry about than just the code
+written for the project.
+
The framework I'd propose is this: If you want to build high-performance systems, focus first on
+reducing performance variance (reducing the gap between the fastest and slowest runs of the same
+code), and only look at average latency once variance is at an acceptable level.
+
Don't get me wrong, I'm a much happier person when things are fast. Computer goes from booting in 20
+seconds down to 10 because I installed a solid-state drive? Awesome. But if every fifth day it takes
+a full minute to boot because of corrupted sectors? Not so great. Average speed over the course of a
+week is the same in each situation, but you're painfully aware of that minute when it happens. When
+it comes to code, the principal is the same: speeding up a function by an average of 10 milliseconds
+doesn't mean much if there's a 100ms difference between your fastest and slowest runs. When
+performance matters, you need to respond quickly every time, not just in aggregate.
+High-performance systems should first optimize for time variance. Once you're consistent at the time
+scale you care about, then focus on improving average time.
+
This focus on variance shows up all the time in industry too (emphasis added in all quotes below):
+
+-
+
In marketing materials for
+NASDAQ's matching engine, the most performance-sensitive component of the exchange, dependability
+is highlighted in addition to instantaneous metrics:
+
+Able to consistently sustain an order rate of over 100,000 orders per second at sub-40
+microsecond average latency
+
+
+-
+
The Aeron message bus has this to say about performance:
+
+Performance is the key focus. Aeron is designed to be the highest throughput with the lowest and
+most predictable latency possible of any messaging system
+
+
+-
+
The company PolySync, which is working on autonomous vehicles,
+mentions why they picked their
+specific messaging format:
+
+In general, high performance is almost always desirable for serialization. But in the world of
+autonomous vehicles, steady timing performance is even more important than peak throughput.
+This is because safe operation is sensitive to timing outliers. Nobody wants the system that
+decides when to slam on the brakes to occasionally take 100 times longer than usual to encode
+its commands.
+
+
+-
+
Solarflare, which makes highly-specialized network hardware, points out
+variance (jitter) as a big concern for
+electronic trading:
+
+The high stakes world of electronic trading, investment banks, market makers, hedge funds and
+exchanges demand the lowest possible latency and jitter while utilizing the highest
+bandwidth and return on their investment.
+
+
+
+
And to further clarify: we're not discussing total run-time, but variance of total run-time. There
+are situations where it's not reasonably possible to make things faster, and you'd much rather be
+consistent. For example, trading firms use
+wireless networks because
+the speed of light through air is faster than through fiber-optic cables. There's still at absolute
+minimum a ~33.76 millisecond delay required to send data between,
+say,
+Chicago and Tokyo.
+If a trading system in Chicago calls the function for "send order to Tokyo" and waits to see if a
+trade occurs, there's a physical limit to how long that will take. In this situation, the focus is
+on keeping variance of additional processing to a minimum, since speed of light is the limiting
+factor.
+
So how does one go about looking for and eliminating performance variance? To tell the truth, I
+don't think a systematic answer or flow-chart exists. There's no substitute for (A) building a deep
+understanding of the entire technology stack, and (B) actually measuring system performance (though
+(C) watching a lot of CppCon videos for
+inspiration never hurt). Even then, every project cares about performance to a different degree; you
+may need to build an entire
+replica production system to
+accurately benchmark at nanosecond precision, or you may be content to simply
+avoid garbage collection in
+your Java code.
+
Even though everyone has different needs, there are still common things to look for when trying to
+isolate and eliminate variance. In no particular order, these are my focus areas when thinking about
+high-performance systems:
+
Update 2019-09-21: Added notes on isolcpus and systemd affinity.
+
Language-specific
+
Garbage Collection: How often does garbage collection happen? When is it triggered? What are the
+impacts?
+
+- In Python, individual objects are collected
+if the reference count reaches 0, and each generation is collected if
+
num_alloc - num_dealloc > gc_threshold whenever an allocation happens. The GIL is acquired for
+the duration of generational collection.
+- Java has
+many
+different
+collection
+algorithms
+to choose from, each with different characteristics. The default algorithms (Parallel GC in Java
+8, G1 in Java 9) freeze the JVM while collecting, while more recent algorithms
+(ZGC and
+Shenandoah) are designed to keep "stop the
+world" to a minimum by doing collection work in parallel.
+
+
Allocation: Every language has a different way of interacting with "heap" memory, but the
+principle is the same: running the allocator to allocate/deallocate memory takes time that can often
+be put to better use. Understanding when your language interacts with the allocator is crucial, and
+not always obvious. For example: C++ and Rust don't allocate heap memory for iterators, but Java
+does (meaning potential GC pauses). Take time to understand heap behavior (I made a
+a guide for Rust), and look into alternative
+allocators (jemalloc,
+tcmalloc) that might run faster than the
+operating system default.
+
Data Layout: How your data is arranged in memory matters;
+data-oriented design and
+cache locality can have huge
+impacts on performance. The C family of languages (C, value types in C#, C++) and Rust all have
+guarantees about the shape every object takes in memory that others (e.g. Java and Python) can't
+make. Cachegrind and kernel
+perf counters are both great for understanding
+how performance relates to memory layout.
+
Just-In-Time Compilation: Languages that are compiled on the fly (LuaJIT, C#, Java, PyPy) are
+great because they optimize your program for how it's actually being used, rather than how a
+compiler expects it to be used. However, there's a variance problem if the program stops executing
+while waiting for translation from VM bytecode to native code. As a remedy, many languages support
+ahead-of-time compilation in addition to the JIT versions
+(CoreRT in C# and GraalVM in Java).
+On the other hand, LLVM supports
+Profile Guided Optimization,
+which theoretically brings JIT benefits to non-JIT languages. Finally, be careful to avoid comparing
+apples and oranges during benchmarks; you don't want your code to suddenly speed up because the JIT
+compiler kicked in.
+
Programming Tricks: These won't make or break performance, but can be useful in specific
+circumstances. For example, C++ can use
+templates instead of branches
+in critical sections.
+
Kernel
+
Code you wrote is almost certainly not the only code running on your hardware. There are many ways
+the operating system interacts with your program, from interrupts to system calls, that are
+important to watch for. These are written from a Linux perspective, but Windows does typically have
+equivalent functionality.
+
Scheduling: The kernel is normally free to schedule any process on any core, so it's important
+to reserve CPU cores exclusively for the important programs. There are a few parts to this: first,
+limit the CPU cores that non-critical processes are allowed to run on by excluding cores from
+scheduling
+(isolcpus
+kernel command-line option), or by setting the init process CPU affinity
+(systemd example). Second, set critical processes
+to run on the isolated cores by setting the
+processor affinity using
+taskset. Finally, use
+NO_HZ or
+chrt to disable scheduling interrupts. Turning off
+hyper-threading is also likely beneficial.
+
System calls: Reading from a UNIX socket? Writing to a file? In addition to not knowing how long
+the I/O operation takes, these all trigger expensive
+system calls (syscalls). To handle these, the CPU must
+context switch to the kernel, let the kernel
+operation complete, then context switch back to your program. We'd rather keep these
+to a minimum (see
+timestamp 18:20). Strace is your friend for understanding when
+and where syscalls happen.
+
Signal Handling: Far less likely to be an issue, but signals do trigger a context switch if your
+code has a handler registered. This will be highly dependent on the application, but you can
+block signals
+if it's an issue.
+
Interrupts: System interrupts are how devices connected to your computer notify the CPU that
+something has happened. The CPU will then choose a processor core to pause and context switch to the
+OS to handle the interrupt. Make sure that
+SMP affinity is
+set so that interrupts are handled on a CPU core not running the program you care about.
+
NUMA: While NUMA is good at making
+multi-cell systems transparent, there are variance implications; if the kernel moves a process
+across nodes, future memory accesses must wait for the controller on the original node. Use
+numactl to handle memory-/cpu-cell pinning so this doesn't
+happen.
+
Hardware
+
CPU Pipelining/Speculation: Speculative execution in modern processors gave us vulnerabilities
+like Spectre, but it also gave us performance improvements like
+branch prediction. And if the CPU mis-speculates
+your code, there's variance associated with rewind and replay. While the compiler knows a lot about
+how your CPU pipelines instructions, code can be
+structured to help the branch
+predictor.
+
Paging: For most systems, virtual memory is incredible. Applications live in their own worlds,
+and the CPU/MMU figures out the details.
+However, there's a variance penalty associated with memory paging and caching; if you access more
+memory pages than the TLB can store,
+you'll have to wait for the page walk. Kernel perf tools are necessary to figure out if this is an
+issue, but using huge pages can
+reduce TLB burdens. Alternately, running applications in a hypervisor like
+Jailhouse allows one to skip virtual memory entirely, but
+this is probably more work than the benefits are worth.
+
Network Interfaces: When more than one computer is involved, variance can go up dramatically.
+Tuning kernel
+network parameters may be
+helpful, but modern systems more frequently opt to skip the kernel altogether with a technique
+called kernel bypass. This typically requires
+specialized hardware and drivers, but even industries like
+telecom are
+finding the benefits.
+
Networks
+
Routing: There's a reason financial firms are willing to pay
+millions of euros
+for rights to a small plot of land - having a straight-line connection from point A to point B means
+the path their data takes is the shortest possible. In contrast, there are currently 6 computers in
+between me and Google, but that may change at any moment if my ISP realizes a
+more efficient route is available. Whether
+it's using
+research-quality equipment
+for shortwave radio, or just making sure there's no data inadvertently going between data centers,
+routing matters.
+
Protocol: TCP as a network protocol is awesome: guaranteed and in-order delivery, flow control,
+and congestion control all built in. But these attributes make the most sense when networking
+infrastructure is lossy; for systems that expect nearly all packets to be delivered correctly, the
+setup handshaking and packet acknowledgment are just overhead. Using UDP (unicast or multicast) may
+make sense in these contexts as it avoids the chatter needed to track connection state, and
+gap-fill
+strategies
+can handle the rest.
+
Switching: Many routers/switches handle packets using "store-and-forward" behavior: wait for the
+whole packet, validate checksums, and then send to the next device. In variance terms, the time
+needed to move data between two nodes is proportional to the size of that data; the switch must
+"store" all data before it can calculate checksums and "forward" to the next node. With
+"cut-through"
+designs, switches will begin forwarding data as soon as they know where the destination is,
+checksums be damned. This means there's a fixed cost (at the switch) for network traffic, no matter
+the size.
+
Final Thoughts
+
High-performance systems, regardless of industry, are not magical. They do require extreme precision
+and attention to detail, but they're designed, built, and operated by regular people, using a lot of
+tools that are publicly available. Interested in seeing how context switching affects performance of
+your benchmarks? taskset should be installed in all modern Linux distributions, and can be used to
+make sure the OS never migrates your process. Curious how often garbage collection triggers during a
+crucial operation? Your language of choice will typically expose details of its operations
+(Python,
+Java).
+Want to know how hard your program is stressing the TLB? Use perf record and look for
+dtlb_load_misses.miss_causes_a_walk.
+
Two final guiding questions, then: first, before attempting to apply some of the technology above to
+your own systems, can you first identify
+where/when you care about "high-performance"? As an
+example, if parts of a system rely on humans pushing buttons, CPU pinning won't have any measurable
+effect. Humans are already far too slow to react in time. Second, if you're using benchmarks, are
+they being designed in a way that's actually helpful? Tools like
+Criterion (also in
+Rust) and Google's
+Benchmark output not only average run time, but variance as
+well; your benchmarking environment is subject to the same concerns your production environment is.
+
Finally, I believe high-performance systems are a matter of philosophy, not necessarily technique.
+Rigorous focus on variance is the first step, and there are plenty of ways to measure and mitigate
+it; once that's at an acceptable level, then optimize for speed.



 +
+ +
+ +
+ +
+
 +
+ +
+ +
+ +
+
























































 -> How I assumed HFT people learn their secret techniques
-
-How else do you explain people working on systems that complete the round trip of market data in to
-orders out (a.k.a. tick-to-trade) consistently within
-[750-800 nanoseconds](https://stackoverflow.com/a/22082528/1454178)? In roughly the time it takes a
-computer to access
-[main memory 8 times](https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html),
-trading systems are capable of reading the market data packets, deciding what orders to send, doing
-risk checks, creating new packets for exchange-specific protocols, and putting those packets on the
-wire.
-
-Having now worked in the trading industry, I can confirm the developers aren't super-human; I've
-made some simple mistakes at the very least. Instead, what shows up in public discussions is that
-philosophy, not technique, separates high-performance systems from everything else.
-Performance-critical systems don't rely on "this one cool C++ optimization trick" to make code fast
-(though micro-optimizations have their place); there's a lot more to worry about than just the code
-written for the project.
-
-The framework I'd propose is this: **If you want to build high-performance systems, focus first on
-reducing performance variance** (reducing the gap between the fastest and slowest runs of the same
-code), **and only look at average latency once variance is at an acceptable level**.
-
-Don't get me wrong, I'm a much happier person when things are fast. Computer goes from booting in 20
-seconds down to 10 because I installed a solid-state drive? Awesome. But if every fifth day it takes
-a full minute to boot because of corrupted sectors? Not so great. Average speed over the course of a
-week is the same in each situation, but you're painfully aware of that minute when it happens. When
-it comes to code, the principal is the same: speeding up a function by an average of 10 milliseconds
-doesn't mean much if there's a 100ms difference between your fastest and slowest runs. When
-performance matters, you need to respond quickly _every time_, not just in aggregate.
-High-performance systems should first optimize for time variance. Once you're consistent at the time
-scale you care about, then focus on improving average time.
-
-This focus on variance shows up all the time in industry too (emphasis added in all quotes below):
-
-- In [marketing materials](https://business.nasdaq.com/market-tech/marketplaces/trading) for
- NASDAQ's matching engine, the most performance-sensitive component of the exchange, dependability
- is highlighted in addition to instantaneous metrics:
-
- > Able to **consistently sustain** an order rate of over 100,000 orders per second at sub-40
- > microsecond average latency
-
-- The [Aeron](https://github.com/real-logic/aeron) message bus has this to say about performance:
-
- > Performance is the key focus. Aeron is designed to be the highest throughput with the lowest and
- > **most predictable latency possible** of any messaging system
-
-- The company PolySync, which is working on autonomous vehicles,
- [mentions why](https://polysync.io/blog/session-types-for-hearty-codecs/) they picked their
- specific messaging format:
-
- > In general, high performance is almost always desirable for serialization. But in the world of
- > autonomous vehicles, **steady timing performance is even more important** than peak throughput.
- > This is because safe operation is sensitive to timing outliers. Nobody wants the system that
- > decides when to slam on the brakes to occasionally take 100 times longer than usual to encode
- > its commands.
-
-- [Solarflare](https://solarflare.com/), which makes highly-specialized network hardware, points out
- variance (jitter) as a big concern for
- [electronic trading](https://solarflare.com/electronic-trading/):
- > The high stakes world of electronic trading, investment banks, market makers, hedge funds and
- > exchanges demand the **lowest possible latency and jitter** while utilizing the highest
- > bandwidth and return on their investment.
-
-And to further clarify: we're not discussing _total run-time_, but variance of total run-time. There
-are situations where it's not reasonably possible to make things faster, and you'd much rather be
-consistent. For example, trading firms use
-[wireless networks](https://sniperinmahwah.wordpress.com/2017/06/07/network-effects-part-i/) because
-the speed of light through air is faster than through fiber-optic cables. There's still at _absolute
-minimum_ a [~33.76 millisecond](http://tinyurl.com/y2vd7tn8) delay required to send data between,
-say,
-[Chicago and Tokyo](https://www.theice.com/market-data/connectivity-and-feeds/wireless/tokyo-chicago).
-If a trading system in Chicago calls the function for "send order to Tokyo" and waits to see if a
-trade occurs, there's a physical limit to how long that will take. In this situation, the focus is
-on keeping variance of _additional processing_ to a minimum, since speed of light is the limiting
-factor.
-
-So how does one go about looking for and eliminating performance variance? To tell the truth, I
-don't think a systematic answer or flow-chart exists. There's no substitute for (A) building a deep
-understanding of the entire technology stack, and (B) actually measuring system performance (though
-(C) watching a lot of [CppCon](https://www.youtube.com/channel/UCMlGfpWw-RUdWX_JbLCukXg) videos for
-inspiration never hurt). Even then, every project cares about performance to a different degree; you
-may need to build an entire
-[replica production system](https://www.youtube.com/watch?v=NH1Tta7purM&feature=youtu.be&t=3015) to
-accurately benchmark at nanosecond precision, or you may be content to simply
-[avoid garbage collection](https://www.youtube.com/watch?v=BD9cRbxWQx8&feature=youtu.be&t=1335) in
-your Java code.
-
-Even though everyone has different needs, there are still common things to look for when trying to
-isolate and eliminate variance. In no particular order, these are my focus areas when thinking about
-high-performance systems:
-
-## Language-specific
-
-**Garbage Collection**: How often does garbage collection happen? When is it triggered? What are the
-impacts?
-
-- [In Python](https://rushter.com/blog/python-garbage-collector/), individual objects are collected
- if the reference count reaches 0, and each generation is collected if
- `num_alloc - num_dealloc > gc_threshold` whenever an allocation happens. The GIL is acquired for
- the duration of generational collection.
-- Java has
- [many](https://docs.oracle.com/en/java/javase/12/gctuning/parallel-collector1.html#GUID-DCDD6E46-0406-41D1-AB49-FB96A50EB9CE)
- [different](https://docs.oracle.com/en/java/javase/12/gctuning/garbage-first-garbage-collector.html#GUID-ED3AB6D3-FD9B-4447-9EDF-983ED2F7A573)
- [collection](https://docs.oracle.com/en/java/javase/12/gctuning/garbage-first-garbage-collector-tuning.html#GUID-90E30ACA-8040-432E-B3A0-1E0440AB556A)
- [algorithms](https://docs.oracle.com/en/java/javase/12/gctuning/z-garbage-collector1.html#GUID-A5A42691-095E-47BA-B6DC-FB4E5FAA43D0)
- to choose from, each with different characteristics. The default algorithms (Parallel GC in Java
- 8, G1 in Java 9) freeze the JVM while collecting, while more recent algorithms
- ([ZGC](https://wiki.openjdk.java.net/display/zgc) and
- [Shenandoah](https://wiki.openjdk.java.net/display/shenandoah)) are designed to keep "stop the
- world" to a minimum by doing collection work in parallel.
-
-**Allocation**: Every language has a different way of interacting with "heap" memory, but the
-principle is the same: running the allocator to allocate/deallocate memory takes time that can often
-be put to better use. Understanding when your language interacts with the allocator is crucial, and
-not always obvious. For example: C++ and Rust don't allocate heap memory for iterators, but Java
-does (meaning potential GC pauses). Take time to understand heap behavior (I made a
-[a guide for Rust](/2019/02/understanding-allocations-in-rust.html)), and look into alternative
-allocators ([jemalloc](http://jemalloc.net/),
-[tcmalloc](https://gperftools.github.io/gperftools/tcmalloc.html)) that might run faster than the
-operating system default.
-
-**Data Layout**: How your data is arranged in memory matters;
-[data-oriented design](https://www.youtube.com/watch?v=yy8jQgmhbAU) and
-[cache locality](https://www.youtube.com/watch?v=2EWejmkKlxs&feature=youtu.be&t=1185) can have huge
-impacts on performance. The C family of languages (C, value types in C#, C++) and Rust all have
-guarantees about the shape every object takes in memory that others (e.g. Java and Python) can't
-make. [Cachegrind](http://valgrind.org/docs/manual/cg-manual.html) and kernel
-[perf](https://perf.wiki.kernel.org/index.php/Main_Page) counters are both great for understanding
-how performance relates to memory layout.
-
-**Just-In-Time Compilation**: Languages that are compiled on the fly (LuaJIT, C#, Java, PyPy) are
-great because they optimize your program for how it's actually being used, rather than how a
-compiler expects it to be used. However, there's a variance problem if the program stops executing
-while waiting for translation from VM bytecode to native code. As a remedy, many languages support
-ahead-of-time compilation in addition to the JIT versions
-([CoreRT](https://github.com/dotnet/corert) in C# and [GraalVM](https://www.graalvm.org/) in Java).
-On the other hand, LLVM supports
-[Profile Guided Optimization](https://clang.llvm.org/docs/UsersManual.html#profile-guided-optimization),
-which theoretically brings JIT benefits to non-JIT languages. Finally, be careful to avoid comparing
-apples and oranges during benchmarks; you don't want your code to suddenly speed up because the JIT
-compiler kicked in.
-
-**Programming Tricks**: These won't make or break performance, but can be useful in specific
-circumstances. For example, C++ can use
-[templates instead of branches](https://www.youtube.com/watch?v=NH1Tta7purM&feature=youtu.be&t=1206)
-in critical sections.
-
-## Kernel
-
-Code you wrote is almost certainly not the _only_ code running on your hardware. There are many ways
-the operating system interacts with your program, from interrupts to system calls, that are
-important to watch for. These are written from a Linux perspective, but Windows does typically have
-equivalent functionality.
-
-**Scheduling**: The kernel is normally free to schedule any process on any core, so it's important
-to reserve CPU cores exclusively for the important programs. There are a few parts to this: first,
-limit the CPU cores that non-critical processes are allowed to run on by excluding cores from
-scheduling
-([`isolcpus`](https://www.linuxtopia.org/online_books/linux_kernel/kernel_configuration/re46.html)
-kernel command-line option), or by setting the `init` process CPU affinity
-([`systemd` example](https://access.redhat.com/solutions/2884991)). Second, set critical processes
-to run on the isolated cores by setting the
-[processor affinity](https://en.wikipedia.org/wiki/Processor_affinity) using
-[taskset](https://linux.die.net/man/1/taskset). Finally, use
-[`NO_HZ`](https://github.com/torvalds/linux/blob/master/Documentation/timers/NO_HZ.txt) or
-[`chrt`](https://linux.die.net/man/1/chrt) to disable scheduling interrupts. Turning off
-hyper-threading is also likely beneficial.
-
-**System calls**: Reading from a UNIX socket? Writing to a file? In addition to not knowing how long
-the I/O operation takes, these all trigger expensive
-[system calls (syscalls)](https://en.wikipedia.org/wiki/System_call). To handle these, the CPU must
-[context switch](https://en.wikipedia.org/wiki/Context_switch) to the kernel, let the kernel
-operation complete, then context switch back to your program. We'd rather keep these
-[to a minimum](https://www.destroyallsoftware.com/talks/the-birth-and-death-of-javascript) (see
-timestamp 18:20). [Strace](https://linux.die.net/man/1/strace) is your friend for understanding when
-and where syscalls happen.
-
-**Signal Handling**: Far less likely to be an issue, but signals do trigger a context switch if your
-code has a handler registered. This will be highly dependent on the application, but you can
-[block signals](https://www.linuxprogrammingblog.com/all-about-linux-signals?page=show#Blocking_signals)
-if it's an issue.
-
-**Interrupts**: System interrupts are how devices connected to your computer notify the CPU that
-something has happened. The CPU will then choose a processor core to pause and context switch to the
-OS to handle the interrupt. Make sure that
-[SMP affinity](http://www.alexonlinux.com/smp-affinity-and-proper-interrupt-handling-in-linux) is
-set so that interrupts are handled on a CPU core not running the program you care about.
-
-**[NUMA](https://www.kernel.org/doc/html/latest/vm/numa.html)**: While NUMA is good at making
-multi-cell systems transparent, there are variance implications; if the kernel moves a process
-across nodes, future memory accesses must wait for the controller on the original node. Use
-[numactl](https://linux.die.net/man/8/numactl) to handle memory-/cpu-cell pinning so this doesn't
-happen.
-
-## Hardware
-
-**CPU Pipelining/Speculation**: Speculative execution in modern processors gave us vulnerabilities
-like Spectre, but it also gave us performance improvements like
-[branch prediction](https://stackoverflow.com/a/11227902/1454178). And if the CPU mis-speculates
-your code, there's variance associated with rewind and replay. While the compiler knows a lot about
-how your CPU [pipelines instructions](https://youtu.be/nAbCKa0FzjQ?t=4467), code can be
-[structured to help](https://www.youtube.com/watch?v=NH1Tta7purM&feature=youtu.be&t=755) the branch
-predictor.
-
-**Paging**: For most systems, virtual memory is incredible. Applications live in their own worlds,
-and the CPU/[MMU](https://en.wikipedia.org/wiki/Memory_management_unit) figures out the details.
-However, there's a variance penalty associated with memory paging and caching; if you access more
-memory pages than the [TLB](https://en.wikipedia.org/wiki/Translation_lookaside_buffer) can store,
-you'll have to wait for the page walk. Kernel perf tools are necessary to figure out if this is an
-issue, but using [huge pages](https://blog.pythian.com/performance-tuning-hugepages-in-linux/) can
-reduce TLB burdens. Alternately, running applications in a hypervisor like
-[Jailhouse](https://github.com/siemens/jailhouse) allows one to skip virtual memory entirely, but
-this is probably more work than the benefits are worth.
-
-**Network Interfaces**: When more than one computer is involved, variance can go up dramatically.
-Tuning kernel
-[network parameters](https://github.com/leandromoreira/linux-network-performance-parameters) may be
-helpful, but modern systems more frequently opt to skip the kernel altogether with a technique
-called [kernel bypass](https://blog.cloudflare.com/kernel-bypass/). This typically requires
-specialized hardware and [drivers](https://www.openonload.org/), but even industries like
-[telecom](https://www.bbc.co.uk/rd/blog/2018-04-high-speed-networking-open-source-kernel-bypass) are
-finding the benefits.
-
-## Networks
-
-**Routing**: There's a reason financial firms are willing to pay
-[millions of euros](https://sniperinmahwah.wordpress.com/2019/03/26/4-les-moeres-english-version/)
-for rights to a small plot of land - having a straight-line connection from point A to point B means
-the path their data takes is the shortest possible. In contrast, there are currently 6 computers in
-between me and Google, but that may change at any moment if my ISP realizes a
-[more efficient route](https://en.wikipedia.org/wiki/Border_Gateway_Protocol) is available. Whether
-it's using
-[research-quality equipment](https://sniperinmahwah.wordpress.com/2018/05/07/shortwave-trading-part-i-the-west-chicago-tower-mystery/)
-for shortwave radio, or just making sure there's no data inadvertently going between data centers,
-routing matters.
-
-**Protocol**: TCP as a network protocol is awesome: guaranteed and in-order delivery, flow control,
-and congestion control all built in. But these attributes make the most sense when networking
-infrastructure is lossy; for systems that expect nearly all packets to be delivered correctly, the
-setup handshaking and packet acknowledgment are just overhead. Using UDP (unicast or multicast) may
-make sense in these contexts as it avoids the chatter needed to track connection state, and
-[gap-fill](https://iextrading.com/docs/IEX%20Transport%20Specification.pdf)
-[strategies](http://www.nasdaqtrader.com/content/technicalsupport/specifications/dataproducts/moldudp64.pdf)
-can handle the rest.
-
-**Switching**: Many routers/switches handle packets using "store-and-forward" behavior: wait for the
-whole packet, validate checksums, and then send to the next device. In variance terms, the time
-needed to move data between two nodes is proportional to the size of that data; the switch must
-"store" all data before it can calculate checksums and "forward" to the next node. With
-["cut-through"](https://www.networkworld.com/article/2241573/latency-and-jitter--cut-through-design-pays-off-for-arista--blade.html)
-designs, switches will begin forwarding data as soon as they know where the destination is,
-checksums be damned. This means there's a fixed cost (at the switch) for network traffic, no matter
-the size.
-
-# Final Thoughts
-
-High-performance systems, regardless of industry, are not magical. They do require extreme precision
-and attention to detail, but they're designed, built, and operated by regular people, using a lot of
-tools that are publicly available. Interested in seeing how context switching affects performance of
-your benchmarks? `taskset` should be installed in all modern Linux distributions, and can be used to
-make sure the OS never migrates your process. Curious how often garbage collection triggers during a
-crucial operation? Your language of choice will typically expose details of its operations
-([Python](https://docs.python.org/3/library/gc.html),
-[Java](https://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html#DebuggingOptions)).
-Want to know how hard your program is stressing the TLB? Use `perf record` and look for
-`dtlb_load_misses.miss_causes_a_walk`.
-
-Two final guiding questions, then: first, before attempting to apply some of the technology above to
-your own systems, can you first identify
-[where/when you care](http://wiki.c2.com/?PrematureOptimization) about "high-performance"? As an
-example, if parts of a system rely on humans pushing buttons, CPU pinning won't have any measurable
-effect. Humans are already far too slow to react in time. Second, if you're using benchmarks, are
-they being designed in a way that's actually helpful? Tools like
-[Criterion](http://www.serpentine.com/criterion/) (also in
-[Rust](https://github.com/bheisler/criterion.rs)) and Google's
-[Benchmark](https://github.com/google/benchmark) output not only average run time, but variance as
-well; your benchmarking environment is subject to the same concerns your production environment is.
-
-Finally, I believe high-performance systems are a matter of philosophy, not necessarily technique.
-Rigorous focus on variance is the first step, and there are plenty of ways to measure and mitigate
-it; once that's at an acceptable level, then optimize for speed.
diff --git a/_posts/2019-09-28-binary-format-shootout.md b/_posts/2019-09-28-binary-format-shootout.md
deleted file mode 100644
index 675dc37..0000000
--- a/_posts/2019-09-28-binary-format-shootout.md
+++ /dev/null
@@ -1,263 +0,0 @@
----
-layout: post
-title: "Binary Format Shootout"
-description: "Cap'n Proto vs. Flatbuffers vs. SBE"
-category:
-tags: [rust]
----
-
-I've found that in many personal projects,
-[analysis paralysis](https://en.wikipedia.org/wiki/Analysis_paralysis) is particularly deadly.
-Making good decisions in the beginning avoids pain and suffering later; if extra research prevents
-future problems, I'm happy to continue ~~procrastinating~~ researching indefinitely.
-
-So let's say you're in need of a binary serialization format. Data will be going over the network,
-not just in memory, so having a schema document and code generation is a must. Performance is
-crucial, so formats that support zero-copy de/serialization are given priority. And the more
-languages supported, the better; I use Rust, but can't predict what other languages this could
-interact with.
-
-Given these requirements, the candidates I could find were:
-
-1. [Cap'n Proto](https://capnproto.org/) has been around the longest, and is the most established
-2. [Flatbuffers](https://google.github.io/flatbuffers/) is the newest, and claims to have a simpler
- encoding
-3. [Simple Binary Encoding](https://github.com/real-logic/simple-binary-encoding) has the simplest
- encoding, but the Rust implementation is unmaintained
-
-Any one of these will satisfy the project requirements: easy to transmit over a network, reasonably
-fast, and polyglot support. But how do you actually pick one? It's impossible to know what issues
-will follow that choice, so I tend to avoid commitment until the last possible moment.
-
-Still, a choice must be made. Instead of worrying about which is "the best," I decided to build a
-small proof-of-concept system in each format and pit them against each other. All code can be found
-in the [repository](https://github.com/speice-io/marketdata-shootout) for this post.
-
-We'll discuss more in detail, but a quick preview of the results:
-
-- Cap'n Proto: Theoretically performs incredibly well, the implementation had issues
-- Flatbuffers: Has some quirks, but largely lived up to its "zero-copy" promises
-- SBE: Best median and worst-case performance, but the message structure has a limited feature set
-
-# Prologue: Binary Parsing with Nom
-
-Our benchmark system will be a simple data processor; given depth-of-book market data from
-[IEX](https://iextrading.com/trading/market-data/#deep), serialize each message into the schema
-format, read it back, and calculate total size of stock traded and the lowest/highest quoted prices.
-This test isn't complex, but is representative of the project I need a binary format for.
-
-But before we make it to that point, we have to actually read in the market data. To do so, I'm
-using a library called [`nom`](https://github.com/Geal/nom). Version 5.0 was recently released and
-brought some big changes, so this was an opportunity to build a non-trivial program and get
-familiar.
-
-If you don't already know about `nom`, it's a "parser generator". By combining different smaller
-parsers, you can assemble a parser to handle complex structures without writing tedious code by
-hand. For example, when parsing
-[PCAP files](https://www.winpcap.org/ntar/draft/PCAP-DumpFileFormat.html#rfc.section.3.3):
-
-```
- 0 1 2 3
- 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
- +---------------------------------------------------------------+
- 0 | Block Type = 0x00000006 |
- +---------------------------------------------------------------+
- 4 | Block Total Length |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- 8 | Interface ID |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
-12 | Timestamp (High) |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
-16 | Timestamp (Low) |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
-20 | Captured Len |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
-24 | Packet Len |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- | Packet Data |
- | ... |
-```
-
-...you can build a parser in `nom` that looks like
-[this](https://github.com/speice-io/marketdata-shootout/blob/369613843d39cfdc728e1003123bf87f79422497/src/parsers.rs#L59-L93):
-
-```rust
-const ENHANCED_PACKET: [u8; 4] = [0x06, 0x00, 0x00, 0x00];
-pub fn enhanced_packet_block(input: &[u8]) -> IResult<&[u8], &[u8]> {
- let (
- remaining,
- (
- block_type,
- block_len,
- interface_id,
- timestamp_high,
- timestamp_low,
- captured_len,
- packet_len,
- ),
- ) = tuple((
- tag(ENHANCED_PACKET),
- le_u32,
- le_u32,
- le_u32,
- le_u32,
- le_u32,
- le_u32,
- ))(input)?;
-
- let (remaining, packet_data) = take(captured_len)(remaining)?;
- Ok((remaining, packet_data))
-}
-```
-
-While this example isn't too interesting, more complex formats (like IEX market data) are where
-[`nom` really shines](https://github.com/speice-io/marketdata-shootout/blob/369613843d39cfdc728e1003123bf87f79422497/src/iex.rs).
-
-Ultimately, because the `nom` code in this shootout was the same for all formats, we're not too
-interested in its performance. Still, it's worth mentioning that building the market data parser was
-actually fun; I didn't have to write tons of boring code by hand.
-
-# Part 1: Cap'n Proto
-
-Now it's time to get into the meaty part of the story. Cap'n Proto was the first format I tried
-because of how long it has supported Rust (thanks to [dwrensha](https://github.com/dwrensha) for
-maintaining the Rust port since
-[2014!](https://github.com/capnproto/capnproto-rust/releases/tag/rustc-0.10)). However, I had a ton
-of performance concerns once I started using it.
-
-To serialize new messages, Cap'n Proto uses a "builder" object. This builder allocates memory on the
-heap to hold the message content, but because builders
-[can't be re-used](https://github.com/capnproto/capnproto-rust/issues/111), we have to allocate a
-new buffer for every single message. I was able to work around this with a
-[special builder](https://github.com/speice-io/marketdata-shootout/blob/369613843d39cfdc728e1003123bf87f79422497/src/capnp_runner.rs#L17-L51)
-that could re-use the buffer, but it required reading through Cap'n Proto's
-[benchmarks](https://github.com/capnproto/capnproto-rust/blob/master/benchmark/benchmark.rs#L124-L156)
-to find an example, and used
-[`std::mem::transmute`](https://doc.rust-lang.org/std/mem/fn.transmute.html) to bypass Rust's borrow
-checker.
-
-The process of reading messages was better, but still had issues. Cap'n Proto has two message
-encodings: a ["packed"](https://capnproto.org/encoding.html#packing) representation, and an
-"unpacked" version. When reading "packed" messages, we need a buffer to unpack the message into
-before we can use it; Cap'n Proto allocates a new buffer for each message we unpack, and I wasn't
-able to figure out a way around that. In contrast, the unpacked message format should be where Cap'n
-Proto shines; its main selling point is that there's [no decoding step](https://capnproto.org/).
-However, accomplishing zero-copy deserialization required code in the private API
-([since fixed](https://github.com/capnproto/capnproto-rust/issues/148)), and we allocate a vector on
-every read for the segment table.
-
-In the end, I put in significant work to make Cap'n Proto as fast as possible, but there were too
-many issues for me to feel comfortable using it long-term.
-
-# Part 2: Flatbuffers
-
-This is the new kid on the block. After a
-[first attempt](https://github.com/google/flatbuffers/pull/3894) didn't pan out, official support
-was [recently launched](https://github.com/google/flatbuffers/pull/4898). Flatbuffers intends to
-address the same problems as Cap'n Proto: high-performance, polyglot, binary messaging. The
-difference is that Flatbuffers claims to have a simpler wire format and
-[more flexibility](https://google.github.io/flatbuffers/flatbuffers_benchmarks.html).
-
-On the whole, I enjoyed using Flatbuffers; the [tooling](https://crates.io/crates/flatc-rust) is
-nice, and unlike Cap'n Proto, parsing messages was actually zero-copy and zero-allocation. However,
-there were still some issues.
-
-First, Flatbuffers (at least in Rust) can't handle nested vectors. This is a problem for formats
-like the following:
-
-```
-table Message {
- symbol: string;
-}
-table MultiMessage {
- messages:[Message];
-}
-```
-
-We want to create a `MultiMessage` which contains a vector of `Message`, and each `Message` itself
-contains a vector (the `string` type). I was able to work around this by
-[caching `Message` elements](https://github.com/speice-io/marketdata-shootout/blob/e9d07d148bf36a211a6f86802b313c4918377d1b/src/flatbuffers_runner.rs#L83)
-in a `SmallVec` before building the final `MultiMessage`, but it was a painful process that I
-believe contributed to poor serialization performance.
-
-Second, streaming support in Flatbuffers seems to be something of an
-[afterthought](https://github.com/google/flatbuffers/issues/3898). Where Cap'n Proto in Rust handles
-reading messages from a stream as part of the API, Flatbuffers just sticks a `u32` at the front of
-each message to indicate the size. Not specifically a problem, but calculating message size without
-that tag is nigh on impossible.
-
-Ultimately, I enjoyed using Flatbuffers, and had to do significantly less work to make it perform
-well.
-
-# Part 3: Simple Binary Encoding
-
-Support for SBE was added by the author of one of my favorite
-[Rust blog posts](https://web.archive.org/web/20190427124806/https://polysync.io/blog/session-types-for-hearty-codecs/).
-I've [talked previously]({% post_url 2019-06-31-high-performance-systems %}) about how important
-variance is in high-performance systems, so it was encouraging to read about a format that
-[directly addressed](https://github.com/real-logic/simple-binary-encoding/wiki/Why-Low-Latency) my
-concerns. SBE has by far the simplest binary format, but it does make some tradeoffs.
-
-Both Cap'n Proto and Flatbuffers use [message offsets](https://capnproto.org/encoding.html#structs)
-to handle variable-length data, [unions](https://capnproto.org/language.html#unions), and various
-other features. In contrast, messages in SBE are essentially
-[just structs](https://github.com/real-logic/simple-binary-encoding/blob/master/sbe-samples/src/main/resources/example-schema.xml);
-variable-length data is supported, but there's no union type.
-
-As mentioned in the beginning, the Rust port of SBE works well, but is
-[essentially unmaintained](https://users.rust-lang.org/t/zero-cost-abstraction-frontier-no-copy-low-allocation-ordered-decoding/11515/9).
-However, if you don't need union types, and can accept that schemas are XML documents, it's still
-worth using. SBE's implementation had the best streaming support of all formats I tested, and
-doesn't trigger allocation during de/serialization.
-
-# Results
-
-After building a test harness
-[for](https://github.com/speice-io/marketdata-shootout/blob/master/src/capnp_runner.rs)
-[each](https://github.com/speice-io/marketdata-shootout/blob/master/src/flatbuffers_runner.rs)
-[format](https://github.com/speice-io/marketdata-shootout/blob/master/src/sbe_runner.rs), it was
-time to actually take them for a spin. I used
-[this script](https://github.com/speice-io/marketdata-shootout/blob/master/run_shootout.sh) to run
-the benchmarks, and the raw results are
-[here](https://github.com/speice-io/marketdata-shootout/blob/master/shootout.csv). All data reported
-below is the average of 10 runs on a single day of IEX data. Results were validated to make sure
-that each format parsed the data correctly.
-
-## Serialization
-
-This test measures, on a
-[per-message basis](https://github.com/speice-io/marketdata-shootout/blob/master/src/main.rs#L268-L272),
-how long it takes to serialize the IEX message into the desired format and write to a pre-allocated
-buffer.
-
-| Schema | Median | 99th Pctl | 99.9th Pctl | Total |
-| :------------------- | :----- | :-------- | :---------- | :----- |
-| Cap'n Proto Packed | 413ns | 1751ns | 2943ns | 14.80s |
-| Cap'n Proto Unpacked | 273ns | 1828ns | 2836ns | 10.65s |
-| Flatbuffers | 355ns | 2185ns | 3497ns | 14.31s |
-| SBE | 91ns | 1535ns | 2423ns | 3.91s |
-
-## Deserialization
-
-This test measures, on a
-[per-message basis](https://github.com/speice-io/marketdata-shootout/blob/master/src/main.rs#L294-L298),
-how long it takes to read the previously-serialized message and perform some basic aggregation. The
-aggregation code is the same for each format, so any performance differences are due solely to the
-format implementation.
-
-| Schema | Median | 99th Pctl | 99.9th Pctl | Total |
-| :------------------- | :----- | :-------- | :---------- | :----- |
-| Cap'n Proto Packed | 539ns | 1216ns | 2599ns | 18.92s |
-| Cap'n Proto Unpacked | 366ns | 737ns | 1583ns | 12.32s |
-| Flatbuffers | 173ns | 421ns | 1007ns | 6.00s |
-| SBE | 116ns | 286ns | 659ns | 4.05s |
-
-# Conclusion
-
-Building a benchmark turned out to be incredibly helpful in making a decision; because a "union"
-type isn't important to me, I can be confident that SBE best addresses my needs.
-
-While SBE was the fastest in terms of both median and worst-case performance, its worst case
-performance was proportionately far higher than any other format. It seems to be that
-de/serialization time scales with message size, but I'll need to do some more research to understand
-what exactly is going on.
diff --git a/_posts/2019-12-14-release-the-gil.md b/_posts/2019-12-14-release-the-gil.md
deleted file mode 100644
index 00b47a6..0000000
--- a/_posts/2019-12-14-release-the-gil.md
+++ /dev/null
@@ -1,370 +0,0 @@
----
-layout: post
-title: "Release the GIL"
-description: "Strategies for Parallelism in Python"
-category:
-tags: [python]
----
-
-Complaining about the [Global Interpreter Lock](https://wiki.python.org/moin/GlobalInterpreterLock)
-(GIL) seems like a rite of passage for Python developers. It's easy to criticize a design decision
-made before multi-core CPU's were widely available, but the fact that it's still around indicates
-that it generally works [Good](https://wiki.c2.com/?PrematureOptimization)
-[Enough](https://wiki.c2.com/?YouArentGonnaNeedIt). Besides, there are simple and effective
-workarounds; it's not hard to start a
-[new process](https://docs.python.org/3/library/multiprocessing.html) and use message passing to
-synchronize code running in parallel.
-
-Still, wouldn't it be nice to have more than a single active interpreter thread? In an age of
-asynchronicity and _M:N_ threading, Python seems lacking. The ideal scenario is to take advantage of
-both Python's productivity and the modern CPU's parallel capabilities.
-
-Presented below are two strategies for releasing the GIL's icy grip without giving up on what makes
-Python a nice language to start with. Bear in mind: these are just the tools, no claim is made about
-whether it's a good idea to use them. Very often, unlocking the GIL is an
-[XY problem](https://en.wikipedia.org/wiki/XY_problem); you want application performance, and the
-GIL seems like an obvious bottleneck. Remember that any gains from running code in parallel come at
-the expense of project complexity; messing with the GIL is ultimately messing with Python's memory
-model.
-
-```python
-%load_ext Cython
-from numba import jit
-
-N = 1_000_000_000
-```
-
-# Cython
-
-Put simply, [Cython](https://cython.org/) is a programming language that looks a lot like Python,
-gets [transpiled](https://en.wikipedia.org/wiki/Source-to-source_compiler) to C/C++, and integrates
-well with the [CPython](https://en.wikipedia.org/wiki/CPython) API. It's great for building Python
-wrappers to C and C++ libraries, writing optimized code for numerical processing, and tons more. And
-when it comes to managing the GIL, there are two special features:
-
-- The `nogil`
- [function annotation](https://cython.readthedocs.io/en/latest/src/userguide/external_C_code.html#declaring-a-function-as-callable-without-the-gil)
- asserts that a Cython function is safe to use without the GIL, and compilation will fail if it
- interacts with Python in an unsafe manner
-- The `with nogil`
- [context manager](https://cython.readthedocs.io/en/latest/src/userguide/external_C_code.html#releasing-the-gil)
- explicitly unlocks the CPython GIL while active
-
-Whenever Cython code runs inside a `with nogil` block on a separate thread, the Python interpreter
-is unblocked and allowed to continue work elsewhere. We'll define a "busy work" function that
-demonstrates this principle in action:
-
-```python
-%%cython
-
-# Annotating a function with `nogil` indicates only that it is safe
-# to call in a `with nogil` block. It *does not* release the GIL.
-cdef unsigned long fibonacci(unsigned long n) nogil:
- if n <= 1:
- return n
-
- cdef unsigned long a = 0, b = 1, c = 0
-
- c = a + b
- for _i in range(2, n):
- a = b
- b = c
- c = a + b
-
- return c
-
-
-def cython_nogil(unsigned long n):
- # Explicitly release the GIL while running `fibonacci`
- with nogil:
- value = fibonacci(n)
-
- return value
-
-
-def cython_gil(unsigned long n):
- # Because the GIL is not explicitly released, it implicitly
- # remains acquired when running the `fibonacci` function
- return fibonacci(n)
-```
-
-First, let's time how long it takes Cython to calculate the billionth Fibonacci number:
-
-```python
-%%time
-_ = cython_gil(N);
-```
-
->
-> How I assumed HFT people learn their secret techniques
-
-How else do you explain people working on systems that complete the round trip of market data in to
-orders out (a.k.a. tick-to-trade) consistently within
-[750-800 nanoseconds](https://stackoverflow.com/a/22082528/1454178)? In roughly the time it takes a
-computer to access
-[main memory 8 times](https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html),
-trading systems are capable of reading the market data packets, deciding what orders to send, doing
-risk checks, creating new packets for exchange-specific protocols, and putting those packets on the
-wire.
-
-Having now worked in the trading industry, I can confirm the developers aren't super-human; I've
-made some simple mistakes at the very least. Instead, what shows up in public discussions is that
-philosophy, not technique, separates high-performance systems from everything else.
-Performance-critical systems don't rely on "this one cool C++ optimization trick" to make code fast
-(though micro-optimizations have their place); there's a lot more to worry about than just the code
-written for the project.
-
-The framework I'd propose is this: **If you want to build high-performance systems, focus first on
-reducing performance variance** (reducing the gap between the fastest and slowest runs of the same
-code), **and only look at average latency once variance is at an acceptable level**.
-
-Don't get me wrong, I'm a much happier person when things are fast. Computer goes from booting in 20
-seconds down to 10 because I installed a solid-state drive? Awesome. But if every fifth day it takes
-a full minute to boot because of corrupted sectors? Not so great. Average speed over the course of a
-week is the same in each situation, but you're painfully aware of that minute when it happens. When
-it comes to code, the principal is the same: speeding up a function by an average of 10 milliseconds
-doesn't mean much if there's a 100ms difference between your fastest and slowest runs. When
-performance matters, you need to respond quickly _every time_, not just in aggregate.
-High-performance systems should first optimize for time variance. Once you're consistent at the time
-scale you care about, then focus on improving average time.
-
-This focus on variance shows up all the time in industry too (emphasis added in all quotes below):
-
-- In [marketing materials](https://business.nasdaq.com/market-tech/marketplaces/trading) for
- NASDAQ's matching engine, the most performance-sensitive component of the exchange, dependability
- is highlighted in addition to instantaneous metrics:
-
- > Able to **consistently sustain** an order rate of over 100,000 orders per second at sub-40
- > microsecond average latency
-
-- The [Aeron](https://github.com/real-logic/aeron) message bus has this to say about performance:
-
- > Performance is the key focus. Aeron is designed to be the highest throughput with the lowest and
- > **most predictable latency possible** of any messaging system
-
-- The company PolySync, which is working on autonomous vehicles,
- [mentions why](https://polysync.io/blog/session-types-for-hearty-codecs/) they picked their
- specific messaging format:
-
- > In general, high performance is almost always desirable for serialization. But in the world of
- > autonomous vehicles, **steady timing performance is even more important** than peak throughput.
- > This is because safe operation is sensitive to timing outliers. Nobody wants the system that
- > decides when to slam on the brakes to occasionally take 100 times longer than usual to encode
- > its commands.
-
-- [Solarflare](https://solarflare.com/), which makes highly-specialized network hardware, points out
- variance (jitter) as a big concern for
- [electronic trading](https://solarflare.com/electronic-trading/):
- > The high stakes world of electronic trading, investment banks, market makers, hedge funds and
- > exchanges demand the **lowest possible latency and jitter** while utilizing the highest
- > bandwidth and return on their investment.
-
-And to further clarify: we're not discussing _total run-time_, but variance of total run-time. There
-are situations where it's not reasonably possible to make things faster, and you'd much rather be
-consistent. For example, trading firms use
-[wireless networks](https://sniperinmahwah.wordpress.com/2017/06/07/network-effects-part-i/) because
-the speed of light through air is faster than through fiber-optic cables. There's still at _absolute
-minimum_ a [~33.76 millisecond](http://tinyurl.com/y2vd7tn8) delay required to send data between,
-say,
-[Chicago and Tokyo](https://www.theice.com/market-data/connectivity-and-feeds/wireless/tokyo-chicago).
-If a trading system in Chicago calls the function for "send order to Tokyo" and waits to see if a
-trade occurs, there's a physical limit to how long that will take. In this situation, the focus is
-on keeping variance of _additional processing_ to a minimum, since speed of light is the limiting
-factor.
-
-So how does one go about looking for and eliminating performance variance? To tell the truth, I
-don't think a systematic answer or flow-chart exists. There's no substitute for (A) building a deep
-understanding of the entire technology stack, and (B) actually measuring system performance (though
-(C) watching a lot of [CppCon](https://www.youtube.com/channel/UCMlGfpWw-RUdWX_JbLCukXg) videos for
-inspiration never hurt). Even then, every project cares about performance to a different degree; you
-may need to build an entire
-[replica production system](https://www.youtube.com/watch?v=NH1Tta7purM&feature=youtu.be&t=3015) to
-accurately benchmark at nanosecond precision, or you may be content to simply
-[avoid garbage collection](https://www.youtube.com/watch?v=BD9cRbxWQx8&feature=youtu.be&t=1335) in
-your Java code.
-
-Even though everyone has different needs, there are still common things to look for when trying to
-isolate and eliminate variance. In no particular order, these are my focus areas when thinking about
-high-performance systems:
-
-## Language-specific
-
-**Garbage Collection**: How often does garbage collection happen? When is it triggered? What are the
-impacts?
-
-- [In Python](https://rushter.com/blog/python-garbage-collector/), individual objects are collected
- if the reference count reaches 0, and each generation is collected if
- `num_alloc - num_dealloc > gc_threshold` whenever an allocation happens. The GIL is acquired for
- the duration of generational collection.
-- Java has
- [many](https://docs.oracle.com/en/java/javase/12/gctuning/parallel-collector1.html#GUID-DCDD6E46-0406-41D1-AB49-FB96A50EB9CE)
- [different](https://docs.oracle.com/en/java/javase/12/gctuning/garbage-first-garbage-collector.html#GUID-ED3AB6D3-FD9B-4447-9EDF-983ED2F7A573)
- [collection](https://docs.oracle.com/en/java/javase/12/gctuning/garbage-first-garbage-collector-tuning.html#GUID-90E30ACA-8040-432E-B3A0-1E0440AB556A)
- [algorithms](https://docs.oracle.com/en/java/javase/12/gctuning/z-garbage-collector1.html#GUID-A5A42691-095E-47BA-B6DC-FB4E5FAA43D0)
- to choose from, each with different characteristics. The default algorithms (Parallel GC in Java
- 8, G1 in Java 9) freeze the JVM while collecting, while more recent algorithms
- ([ZGC](https://wiki.openjdk.java.net/display/zgc) and
- [Shenandoah](https://wiki.openjdk.java.net/display/shenandoah)) are designed to keep "stop the
- world" to a minimum by doing collection work in parallel.
-
-**Allocation**: Every language has a different way of interacting with "heap" memory, but the
-principle is the same: running the allocator to allocate/deallocate memory takes time that can often
-be put to better use. Understanding when your language interacts with the allocator is crucial, and
-not always obvious. For example: C++ and Rust don't allocate heap memory for iterators, but Java
-does (meaning potential GC pauses). Take time to understand heap behavior (I made a
-[a guide for Rust](/2019/02/understanding-allocations-in-rust.html)), and look into alternative
-allocators ([jemalloc](http://jemalloc.net/),
-[tcmalloc](https://gperftools.github.io/gperftools/tcmalloc.html)) that might run faster than the
-operating system default.
-
-**Data Layout**: How your data is arranged in memory matters;
-[data-oriented design](https://www.youtube.com/watch?v=yy8jQgmhbAU) and
-[cache locality](https://www.youtube.com/watch?v=2EWejmkKlxs&feature=youtu.be&t=1185) can have huge
-impacts on performance. The C family of languages (C, value types in C#, C++) and Rust all have
-guarantees about the shape every object takes in memory that others (e.g. Java and Python) can't
-make. [Cachegrind](http://valgrind.org/docs/manual/cg-manual.html) and kernel
-[perf](https://perf.wiki.kernel.org/index.php/Main_Page) counters are both great for understanding
-how performance relates to memory layout.
-
-**Just-In-Time Compilation**: Languages that are compiled on the fly (LuaJIT, C#, Java, PyPy) are
-great because they optimize your program for how it's actually being used, rather than how a
-compiler expects it to be used. However, there's a variance problem if the program stops executing
-while waiting for translation from VM bytecode to native code. As a remedy, many languages support
-ahead-of-time compilation in addition to the JIT versions
-([CoreRT](https://github.com/dotnet/corert) in C# and [GraalVM](https://www.graalvm.org/) in Java).
-On the other hand, LLVM supports
-[Profile Guided Optimization](https://clang.llvm.org/docs/UsersManual.html#profile-guided-optimization),
-which theoretically brings JIT benefits to non-JIT languages. Finally, be careful to avoid comparing
-apples and oranges during benchmarks; you don't want your code to suddenly speed up because the JIT
-compiler kicked in.
-
-**Programming Tricks**: These won't make or break performance, but can be useful in specific
-circumstances. For example, C++ can use
-[templates instead of branches](https://www.youtube.com/watch?v=NH1Tta7purM&feature=youtu.be&t=1206)
-in critical sections.
-
-## Kernel
-
-Code you wrote is almost certainly not the _only_ code running on your hardware. There are many ways
-the operating system interacts with your program, from interrupts to system calls, that are
-important to watch for. These are written from a Linux perspective, but Windows does typically have
-equivalent functionality.
-
-**Scheduling**: The kernel is normally free to schedule any process on any core, so it's important
-to reserve CPU cores exclusively for the important programs. There are a few parts to this: first,
-limit the CPU cores that non-critical processes are allowed to run on by excluding cores from
-scheduling
-([`isolcpus`](https://www.linuxtopia.org/online_books/linux_kernel/kernel_configuration/re46.html)
-kernel command-line option), or by setting the `init` process CPU affinity
-([`systemd` example](https://access.redhat.com/solutions/2884991)). Second, set critical processes
-to run on the isolated cores by setting the
-[processor affinity](https://en.wikipedia.org/wiki/Processor_affinity) using
-[taskset](https://linux.die.net/man/1/taskset). Finally, use
-[`NO_HZ`](https://github.com/torvalds/linux/blob/master/Documentation/timers/NO_HZ.txt) or
-[`chrt`](https://linux.die.net/man/1/chrt) to disable scheduling interrupts. Turning off
-hyper-threading is also likely beneficial.
-
-**System calls**: Reading from a UNIX socket? Writing to a file? In addition to not knowing how long
-the I/O operation takes, these all trigger expensive
-[system calls (syscalls)](https://en.wikipedia.org/wiki/System_call). To handle these, the CPU must
-[context switch](https://en.wikipedia.org/wiki/Context_switch) to the kernel, let the kernel
-operation complete, then context switch back to your program. We'd rather keep these
-[to a minimum](https://www.destroyallsoftware.com/talks/the-birth-and-death-of-javascript) (see
-timestamp 18:20). [Strace](https://linux.die.net/man/1/strace) is your friend for understanding when
-and where syscalls happen.
-
-**Signal Handling**: Far less likely to be an issue, but signals do trigger a context switch if your
-code has a handler registered. This will be highly dependent on the application, but you can
-[block signals](https://www.linuxprogrammingblog.com/all-about-linux-signals?page=show#Blocking_signals)
-if it's an issue.
-
-**Interrupts**: System interrupts are how devices connected to your computer notify the CPU that
-something has happened. The CPU will then choose a processor core to pause and context switch to the
-OS to handle the interrupt. Make sure that
-[SMP affinity](http://www.alexonlinux.com/smp-affinity-and-proper-interrupt-handling-in-linux) is
-set so that interrupts are handled on a CPU core not running the program you care about.
-
-**[NUMA](https://www.kernel.org/doc/html/latest/vm/numa.html)**: While NUMA is good at making
-multi-cell systems transparent, there are variance implications; if the kernel moves a process
-across nodes, future memory accesses must wait for the controller on the original node. Use
-[numactl](https://linux.die.net/man/8/numactl) to handle memory-/cpu-cell pinning so this doesn't
-happen.
-
-## Hardware
-
-**CPU Pipelining/Speculation**: Speculative execution in modern processors gave us vulnerabilities
-like Spectre, but it also gave us performance improvements like
-[branch prediction](https://stackoverflow.com/a/11227902/1454178). And if the CPU mis-speculates
-your code, there's variance associated with rewind and replay. While the compiler knows a lot about
-how your CPU [pipelines instructions](https://youtu.be/nAbCKa0FzjQ?t=4467), code can be
-[structured to help](https://www.youtube.com/watch?v=NH1Tta7purM&feature=youtu.be&t=755) the branch
-predictor.
-
-**Paging**: For most systems, virtual memory is incredible. Applications live in their own worlds,
-and the CPU/[MMU](https://en.wikipedia.org/wiki/Memory_management_unit) figures out the details.
-However, there's a variance penalty associated with memory paging and caching; if you access more
-memory pages than the [TLB](https://en.wikipedia.org/wiki/Translation_lookaside_buffer) can store,
-you'll have to wait for the page walk. Kernel perf tools are necessary to figure out if this is an
-issue, but using [huge pages](https://blog.pythian.com/performance-tuning-hugepages-in-linux/) can
-reduce TLB burdens. Alternately, running applications in a hypervisor like
-[Jailhouse](https://github.com/siemens/jailhouse) allows one to skip virtual memory entirely, but
-this is probably more work than the benefits are worth.
-
-**Network Interfaces**: When more than one computer is involved, variance can go up dramatically.
-Tuning kernel
-[network parameters](https://github.com/leandromoreira/linux-network-performance-parameters) may be
-helpful, but modern systems more frequently opt to skip the kernel altogether with a technique
-called [kernel bypass](https://blog.cloudflare.com/kernel-bypass/). This typically requires
-specialized hardware and [drivers](https://www.openonload.org/), but even industries like
-[telecom](https://www.bbc.co.uk/rd/blog/2018-04-high-speed-networking-open-source-kernel-bypass) are
-finding the benefits.
-
-## Networks
-
-**Routing**: There's a reason financial firms are willing to pay
-[millions of euros](https://sniperinmahwah.wordpress.com/2019/03/26/4-les-moeres-english-version/)
-for rights to a small plot of land - having a straight-line connection from point A to point B means
-the path their data takes is the shortest possible. In contrast, there are currently 6 computers in
-between me and Google, but that may change at any moment if my ISP realizes a
-[more efficient route](https://en.wikipedia.org/wiki/Border_Gateway_Protocol) is available. Whether
-it's using
-[research-quality equipment](https://sniperinmahwah.wordpress.com/2018/05/07/shortwave-trading-part-i-the-west-chicago-tower-mystery/)
-for shortwave radio, or just making sure there's no data inadvertently going between data centers,
-routing matters.
-
-**Protocol**: TCP as a network protocol is awesome: guaranteed and in-order delivery, flow control,
-and congestion control all built in. But these attributes make the most sense when networking
-infrastructure is lossy; for systems that expect nearly all packets to be delivered correctly, the
-setup handshaking and packet acknowledgment are just overhead. Using UDP (unicast or multicast) may
-make sense in these contexts as it avoids the chatter needed to track connection state, and
-[gap-fill](https://iextrading.com/docs/IEX%20Transport%20Specification.pdf)
-[strategies](http://www.nasdaqtrader.com/content/technicalsupport/specifications/dataproducts/moldudp64.pdf)
-can handle the rest.
-
-**Switching**: Many routers/switches handle packets using "store-and-forward" behavior: wait for the
-whole packet, validate checksums, and then send to the next device. In variance terms, the time
-needed to move data between two nodes is proportional to the size of that data; the switch must
-"store" all data before it can calculate checksums and "forward" to the next node. With
-["cut-through"](https://www.networkworld.com/article/2241573/latency-and-jitter--cut-through-design-pays-off-for-arista--blade.html)
-designs, switches will begin forwarding data as soon as they know where the destination is,
-checksums be damned. This means there's a fixed cost (at the switch) for network traffic, no matter
-the size.
-
-# Final Thoughts
-
-High-performance systems, regardless of industry, are not magical. They do require extreme precision
-and attention to detail, but they're designed, built, and operated by regular people, using a lot of
-tools that are publicly available. Interested in seeing how context switching affects performance of
-your benchmarks? `taskset` should be installed in all modern Linux distributions, and can be used to
-make sure the OS never migrates your process. Curious how often garbage collection triggers during a
-crucial operation? Your language of choice will typically expose details of its operations
-([Python](https://docs.python.org/3/library/gc.html),
-[Java](https://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html#DebuggingOptions)).
-Want to know how hard your program is stressing the TLB? Use `perf record` and look for
-`dtlb_load_misses.miss_causes_a_walk`.
-
-Two final guiding questions, then: first, before attempting to apply some of the technology above to
-your own systems, can you first identify
-[where/when you care](http://wiki.c2.com/?PrematureOptimization) about "high-performance"? As an
-example, if parts of a system rely on humans pushing buttons, CPU pinning won't have any measurable
-effect. Humans are already far too slow to react in time. Second, if you're using benchmarks, are
-they being designed in a way that's actually helpful? Tools like
-[Criterion](http://www.serpentine.com/criterion/) (also in
-[Rust](https://github.com/bheisler/criterion.rs)) and Google's
-[Benchmark](https://github.com/google/benchmark) output not only average run time, but variance as
-well; your benchmarking environment is subject to the same concerns your production environment is.
-
-Finally, I believe high-performance systems are a matter of philosophy, not necessarily technique.
-Rigorous focus on variance is the first step, and there are plenty of ways to measure and mitigate
-it; once that's at an acceptable level, then optimize for speed.
diff --git a/_posts/2019-09-28-binary-format-shootout.md b/_posts/2019-09-28-binary-format-shootout.md
deleted file mode 100644
index 675dc37..0000000
--- a/_posts/2019-09-28-binary-format-shootout.md
+++ /dev/null
@@ -1,263 +0,0 @@
----
-layout: post
-title: "Binary Format Shootout"
-description: "Cap'n Proto vs. Flatbuffers vs. SBE"
-category:
-tags: [rust]
----
-
-I've found that in many personal projects,
-[analysis paralysis](https://en.wikipedia.org/wiki/Analysis_paralysis) is particularly deadly.
-Making good decisions in the beginning avoids pain and suffering later; if extra research prevents
-future problems, I'm happy to continue ~~procrastinating~~ researching indefinitely.
-
-So let's say you're in need of a binary serialization format. Data will be going over the network,
-not just in memory, so having a schema document and code generation is a must. Performance is
-crucial, so formats that support zero-copy de/serialization are given priority. And the more
-languages supported, the better; I use Rust, but can't predict what other languages this could
-interact with.
-
-Given these requirements, the candidates I could find were:
-
-1. [Cap'n Proto](https://capnproto.org/) has been around the longest, and is the most established
-2. [Flatbuffers](https://google.github.io/flatbuffers/) is the newest, and claims to have a simpler
- encoding
-3. [Simple Binary Encoding](https://github.com/real-logic/simple-binary-encoding) has the simplest
- encoding, but the Rust implementation is unmaintained
-
-Any one of these will satisfy the project requirements: easy to transmit over a network, reasonably
-fast, and polyglot support. But how do you actually pick one? It's impossible to know what issues
-will follow that choice, so I tend to avoid commitment until the last possible moment.
-
-Still, a choice must be made. Instead of worrying about which is "the best," I decided to build a
-small proof-of-concept system in each format and pit them against each other. All code can be found
-in the [repository](https://github.com/speice-io/marketdata-shootout) for this post.
-
-We'll discuss more in detail, but a quick preview of the results:
-
-- Cap'n Proto: Theoretically performs incredibly well, the implementation had issues
-- Flatbuffers: Has some quirks, but largely lived up to its "zero-copy" promises
-- SBE: Best median and worst-case performance, but the message structure has a limited feature set
-
-# Prologue: Binary Parsing with Nom
-
-Our benchmark system will be a simple data processor; given depth-of-book market data from
-[IEX](https://iextrading.com/trading/market-data/#deep), serialize each message into the schema
-format, read it back, and calculate total size of stock traded and the lowest/highest quoted prices.
-This test isn't complex, but is representative of the project I need a binary format for.
-
-But before we make it to that point, we have to actually read in the market data. To do so, I'm
-using a library called [`nom`](https://github.com/Geal/nom). Version 5.0 was recently released and
-brought some big changes, so this was an opportunity to build a non-trivial program and get
-familiar.
-
-If you don't already know about `nom`, it's a "parser generator". By combining different smaller
-parsers, you can assemble a parser to handle complex structures without writing tedious code by
-hand. For example, when parsing
-[PCAP files](https://www.winpcap.org/ntar/draft/PCAP-DumpFileFormat.html#rfc.section.3.3):
-
-```
- 0 1 2 3
- 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
- +---------------------------------------------------------------+
- 0 | Block Type = 0x00000006 |
- +---------------------------------------------------------------+
- 4 | Block Total Length |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- 8 | Interface ID |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
-12 | Timestamp (High) |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
-16 | Timestamp (Low) |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
-20 | Captured Len |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
-24 | Packet Len |
- +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- | Packet Data |
- | ... |
-```
-
-...you can build a parser in `nom` that looks like
-[this](https://github.com/speice-io/marketdata-shootout/blob/369613843d39cfdc728e1003123bf87f79422497/src/parsers.rs#L59-L93):
-
-```rust
-const ENHANCED_PACKET: [u8; 4] = [0x06, 0x00, 0x00, 0x00];
-pub fn enhanced_packet_block(input: &[u8]) -> IResult<&[u8], &[u8]> {
- let (
- remaining,
- (
- block_type,
- block_len,
- interface_id,
- timestamp_high,
- timestamp_low,
- captured_len,
- packet_len,
- ),
- ) = tuple((
- tag(ENHANCED_PACKET),
- le_u32,
- le_u32,
- le_u32,
- le_u32,
- le_u32,
- le_u32,
- ))(input)?;
-
- let (remaining, packet_data) = take(captured_len)(remaining)?;
- Ok((remaining, packet_data))
-}
-```
-
-While this example isn't too interesting, more complex formats (like IEX market data) are where
-[`nom` really shines](https://github.com/speice-io/marketdata-shootout/blob/369613843d39cfdc728e1003123bf87f79422497/src/iex.rs).
-
-Ultimately, because the `nom` code in this shootout was the same for all formats, we're not too
-interested in its performance. Still, it's worth mentioning that building the market data parser was
-actually fun; I didn't have to write tons of boring code by hand.
-
-# Part 1: Cap'n Proto
-
-Now it's time to get into the meaty part of the story. Cap'n Proto was the first format I tried
-because of how long it has supported Rust (thanks to [dwrensha](https://github.com/dwrensha) for
-maintaining the Rust port since
-[2014!](https://github.com/capnproto/capnproto-rust/releases/tag/rustc-0.10)). However, I had a ton
-of performance concerns once I started using it.
-
-To serialize new messages, Cap'n Proto uses a "builder" object. This builder allocates memory on the
-heap to hold the message content, but because builders
-[can't be re-used](https://github.com/capnproto/capnproto-rust/issues/111), we have to allocate a
-new buffer for every single message. I was able to work around this with a
-[special builder](https://github.com/speice-io/marketdata-shootout/blob/369613843d39cfdc728e1003123bf87f79422497/src/capnp_runner.rs#L17-L51)
-that could re-use the buffer, but it required reading through Cap'n Proto's
-[benchmarks](https://github.com/capnproto/capnproto-rust/blob/master/benchmark/benchmark.rs#L124-L156)
-to find an example, and used
-[`std::mem::transmute`](https://doc.rust-lang.org/std/mem/fn.transmute.html) to bypass Rust's borrow
-checker.
-
-The process of reading messages was better, but still had issues. Cap'n Proto has two message
-encodings: a ["packed"](https://capnproto.org/encoding.html#packing) representation, and an
-"unpacked" version. When reading "packed" messages, we need a buffer to unpack the message into
-before we can use it; Cap'n Proto allocates a new buffer for each message we unpack, and I wasn't
-able to figure out a way around that. In contrast, the unpacked message format should be where Cap'n
-Proto shines; its main selling point is that there's [no decoding step](https://capnproto.org/).
-However, accomplishing zero-copy deserialization required code in the private API
-([since fixed](https://github.com/capnproto/capnproto-rust/issues/148)), and we allocate a vector on
-every read for the segment table.
-
-In the end, I put in significant work to make Cap'n Proto as fast as possible, but there were too
-many issues for me to feel comfortable using it long-term.
-
-# Part 2: Flatbuffers
-
-This is the new kid on the block. After a
-[first attempt](https://github.com/google/flatbuffers/pull/3894) didn't pan out, official support
-was [recently launched](https://github.com/google/flatbuffers/pull/4898). Flatbuffers intends to
-address the same problems as Cap'n Proto: high-performance, polyglot, binary messaging. The
-difference is that Flatbuffers claims to have a simpler wire format and
-[more flexibility](https://google.github.io/flatbuffers/flatbuffers_benchmarks.html).
-
-On the whole, I enjoyed using Flatbuffers; the [tooling](https://crates.io/crates/flatc-rust) is
-nice, and unlike Cap'n Proto, parsing messages was actually zero-copy and zero-allocation. However,
-there were still some issues.
-
-First, Flatbuffers (at least in Rust) can't handle nested vectors. This is a problem for formats
-like the following:
-
-```
-table Message {
- symbol: string;
-}
-table MultiMessage {
- messages:[Message];
-}
-```
-
-We want to create a `MultiMessage` which contains a vector of `Message`, and each `Message` itself
-contains a vector (the `string` type). I was able to work around this by
-[caching `Message` elements](https://github.com/speice-io/marketdata-shootout/blob/e9d07d148bf36a211a6f86802b313c4918377d1b/src/flatbuffers_runner.rs#L83)
-in a `SmallVec` before building the final `MultiMessage`, but it was a painful process that I
-believe contributed to poor serialization performance.
-
-Second, streaming support in Flatbuffers seems to be something of an
-[afterthought](https://github.com/google/flatbuffers/issues/3898). Where Cap'n Proto in Rust handles
-reading messages from a stream as part of the API, Flatbuffers just sticks a `u32` at the front of
-each message to indicate the size. Not specifically a problem, but calculating message size without
-that tag is nigh on impossible.
-
-Ultimately, I enjoyed using Flatbuffers, and had to do significantly less work to make it perform
-well.
-
-# Part 3: Simple Binary Encoding
-
-Support for SBE was added by the author of one of my favorite
-[Rust blog posts](https://web.archive.org/web/20190427124806/https://polysync.io/blog/session-types-for-hearty-codecs/).
-I've [talked previously]({% post_url 2019-06-31-high-performance-systems %}) about how important
-variance is in high-performance systems, so it was encouraging to read about a format that
-[directly addressed](https://github.com/real-logic/simple-binary-encoding/wiki/Why-Low-Latency) my
-concerns. SBE has by far the simplest binary format, but it does make some tradeoffs.
-
-Both Cap'n Proto and Flatbuffers use [message offsets](https://capnproto.org/encoding.html#structs)
-to handle variable-length data, [unions](https://capnproto.org/language.html#unions), and various
-other features. In contrast, messages in SBE are essentially
-[just structs](https://github.com/real-logic/simple-binary-encoding/blob/master/sbe-samples/src/main/resources/example-schema.xml);
-variable-length data is supported, but there's no union type.
-
-As mentioned in the beginning, the Rust port of SBE works well, but is
-[essentially unmaintained](https://users.rust-lang.org/t/zero-cost-abstraction-frontier-no-copy-low-allocation-ordered-decoding/11515/9).
-However, if you don't need union types, and can accept that schemas are XML documents, it's still
-worth using. SBE's implementation had the best streaming support of all formats I tested, and
-doesn't trigger allocation during de/serialization.
-
-# Results
-
-After building a test harness
-[for](https://github.com/speice-io/marketdata-shootout/blob/master/src/capnp_runner.rs)
-[each](https://github.com/speice-io/marketdata-shootout/blob/master/src/flatbuffers_runner.rs)
-[format](https://github.com/speice-io/marketdata-shootout/blob/master/src/sbe_runner.rs), it was
-time to actually take them for a spin. I used
-[this script](https://github.com/speice-io/marketdata-shootout/blob/master/run_shootout.sh) to run
-the benchmarks, and the raw results are
-[here](https://github.com/speice-io/marketdata-shootout/blob/master/shootout.csv). All data reported
-below is the average of 10 runs on a single day of IEX data. Results were validated to make sure
-that each format parsed the data correctly.
-
-## Serialization
-
-This test measures, on a
-[per-message basis](https://github.com/speice-io/marketdata-shootout/blob/master/src/main.rs#L268-L272),
-how long it takes to serialize the IEX message into the desired format and write to a pre-allocated
-buffer.
-
-| Schema | Median | 99th Pctl | 99.9th Pctl | Total |
-| :------------------- | :----- | :-------- | :---------- | :----- |
-| Cap'n Proto Packed | 413ns | 1751ns | 2943ns | 14.80s |
-| Cap'n Proto Unpacked | 273ns | 1828ns | 2836ns | 10.65s |
-| Flatbuffers | 355ns | 2185ns | 3497ns | 14.31s |
-| SBE | 91ns | 1535ns | 2423ns | 3.91s |
-
-## Deserialization
-
-This test measures, on a
-[per-message basis](https://github.com/speice-io/marketdata-shootout/blob/master/src/main.rs#L294-L298),
-how long it takes to read the previously-serialized message and perform some basic aggregation. The
-aggregation code is the same for each format, so any performance differences are due solely to the
-format implementation.
-
-| Schema | Median | 99th Pctl | 99.9th Pctl | Total |
-| :------------------- | :----- | :-------- | :---------- | :----- |
-| Cap'n Proto Packed | 539ns | 1216ns | 2599ns | 18.92s |
-| Cap'n Proto Unpacked | 366ns | 737ns | 1583ns | 12.32s |
-| Flatbuffers | 173ns | 421ns | 1007ns | 6.00s |
-| SBE | 116ns | 286ns | 659ns | 4.05s |
-
-# Conclusion
-
-Building a benchmark turned out to be incredibly helpful in making a decision; because a "union"
-type isn't important to me, I can be confident that SBE best addresses my needs.
-
-While SBE was the fastest in terms of both median and worst-case performance, its worst case
-performance was proportionately far higher than any other format. It seems to be that
-de/serialization time scales with message size, but I'll need to do some more research to understand
-what exactly is going on.
diff --git a/_posts/2019-12-14-release-the-gil.md b/_posts/2019-12-14-release-the-gil.md
deleted file mode 100644
index 00b47a6..0000000
--- a/_posts/2019-12-14-release-the-gil.md
+++ /dev/null
@@ -1,370 +0,0 @@
----
-layout: post
-title: "Release the GIL"
-description: "Strategies for Parallelism in Python"
-category:
-tags: [python]
----
-
-Complaining about the [Global Interpreter Lock](https://wiki.python.org/moin/GlobalInterpreterLock)
-(GIL) seems like a rite of passage for Python developers. It's easy to criticize a design decision
-made before multi-core CPU's were widely available, but the fact that it's still around indicates
-that it generally works [Good](https://wiki.c2.com/?PrematureOptimization)
-[Enough](https://wiki.c2.com/?YouArentGonnaNeedIt). Besides, there are simple and effective
-workarounds; it's not hard to start a
-[new process](https://docs.python.org/3/library/multiprocessing.html) and use message passing to
-synchronize code running in parallel.
-
-Still, wouldn't it be nice to have more than a single active interpreter thread? In an age of
-asynchronicity and _M:N_ threading, Python seems lacking. The ideal scenario is to take advantage of
-both Python's productivity and the modern CPU's parallel capabilities.
-
-Presented below are two strategies for releasing the GIL's icy grip without giving up on what makes
-Python a nice language to start with. Bear in mind: these are just the tools, no claim is made about
-whether it's a good idea to use them. Very often, unlocking the GIL is an
-[XY problem](https://en.wikipedia.org/wiki/XY_problem); you want application performance, and the
-GIL seems like an obvious bottleneck. Remember that any gains from running code in parallel come at
-the expense of project complexity; messing with the GIL is ultimately messing with Python's memory
-model.
-
-```python
-%load_ext Cython
-from numba import jit
-
-N = 1_000_000_000
-```
-
-# Cython
-
-Put simply, [Cython](https://cython.org/) is a programming language that looks a lot like Python,
-gets [transpiled](https://en.wikipedia.org/wiki/Source-to-source_compiler) to C/C++, and integrates
-well with the [CPython](https://en.wikipedia.org/wiki/CPython) API. It's great for building Python
-wrappers to C and C++ libraries, writing optimized code for numerical processing, and tons more. And
-when it comes to managing the GIL, there are two special features:
-
-- The `nogil`
- [function annotation](https://cython.readthedocs.io/en/latest/src/userguide/external_C_code.html#declaring-a-function-as-callable-without-the-gil)
- asserts that a Cython function is safe to use without the GIL, and compilation will fail if it
- interacts with Python in an unsafe manner
-- The `with nogil`
- [context manager](https://cython.readthedocs.io/en/latest/src/userguide/external_C_code.html#releasing-the-gil)
- explicitly unlocks the CPython GIL while active
-
-Whenever Cython code runs inside a `with nogil` block on a separate thread, the Python interpreter
-is unblocked and allowed to continue work elsewhere. We'll define a "busy work" function that
-demonstrates this principle in action:
-
-```python
-%%cython
-
-# Annotating a function with `nogil` indicates only that it is safe
-# to call in a `with nogil` block. It *does not* release the GIL.
-cdef unsigned long fibonacci(unsigned long n) nogil:
- if n <= 1:
- return n
-
- cdef unsigned long a = 0, b = 1, c = 0
-
- c = a + b
- for _i in range(2, n):
- a = b
- b = c
- c = a + b
-
- return c
-
-
-def cython_nogil(unsigned long n):
- # Explicitly release the GIL while running `fibonacci`
- with nogil:
- value = fibonacci(n)
-
- return value
-
-
-def cython_gil(unsigned long n):
- # Because the GIL is not explicitly released, it implicitly
- # remains acquired when running the `fibonacci` function
- return fibonacci(n)
-```
-
-First, let's time how long it takes Cython to calculate the billionth Fibonacci number:
-
-```python
-%%time
-_ = cython_gil(N);
-```
-
->